Using LLMs and Vector Stores to search the Berkshire Hathaway Letters
Extracting information from text can be a time consuming task, especially when you’re looking for a needle in a haystack. Warren Buffett has had a long and successful (perhaps the most successful?) career in investing and provides a number of anecdotes and words of wisdom in the form the Berkshire Hathaway shareholder letters. In this blog post I will lay out a method of extracting this wisdom via embeddings, a vector store, a large language model and a search interface via Streamlit.
The Streamlit application allows for the user to enter a question, then receive back the associated documents for the question as well as the answer to the submitted question.
Technologies used
- Langchain - used to assembled queries to the Large Language Model (LLM) and the vector store (Postgres/PG Vector)
- OpenAI - Provides an API to access Large Language Models (LLMs) and generate embeddings
- Postgres/PGVector (hosted via Neon) - used to store and query embeddings generated by OpenAI
Methodology
The process is split into two stages. First we extract the embeddings, then we query the embeddings and pass the data to a large language model for question answering.
Extraction steps (extract embeddings from PDF and load into PostgreSQL/pgvector):
- Use a PDF loader to read each PDF, splitting the text into chunks of 500 characters with no overlap.
- Concatenate all of these chunks into a list of chunks.
- Use the Langchain
PGVectormodule to generate embeddings based off of chunks and store them in Postgres.
Query steps (Retrieve documents via similarity search (cosine similarity) and use an LLM to process those documents):
- Use the Langchain
PGVectormodule to perform a similarity search against the stored embeddings based on the query. - Use
RetrievalQAchain to use those embeddings to answer the provided query.
Extraction Stage - Source Code Overview
The following blocks of code reads the document, splits it into chunks, and uses the from_documents function from the PGVector module to compute the embeddings using the OpenAIEmbeddings module. The PDFs are from each year, the first years are created from the HTML provided at the Berkshire Hathaway website exported as PDF, the more recent letters are from the PDFs provided on the site.
Note: Imports have been omitted for brevity.
Load documents and chunk them into 500 character chunks:
chunks = []
# Scan and split each document and load into the documents array
for pdf in os.listdir("content/letters/pdfs"):
filename = f"content/letters/pdfs/{pdf}"
print(f"Splitting file: {filename}")
loader = OnlinePDFLoader(filename)
data = loader.load()
chunk_size = 500 # break document up into 500 character chunks
chunk_overlap = 0 # avoid any overlap in chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
all_splits = text_splitter.split_documents(data)
for a in all_splits:
chunks.append(a)
Compute embeddings from the document and load them in the vector store:
# Class that allows us to easily compute embeddings via OpenAI's APIs
embeddings = OpenAIEmbeddings()
# Connection string to the Postgres instance with the pgvector extension enabled
connection_string = os.getenv("EMBEDDINGS_DB_CONNECTION_STRING")
collection_name = "letters"
# Now we load the chunks, compute embeddings from them and load them into the vector store
# pre_delete_collection set to true will delete an existing collection and reload it
# which is useful for debugging
pre_delete_collection = True
vector_store = PGVector.from_documents(
embedding=embeddings,
documents=chunks,
collection_name=collection_name,
connection_string=connection_string,
pre_delete_collection=pre_delete_collection
)
# At this point the embeddings will be stored and ready for use
Perform a query against the embeddings stored in the vector store:
# Find similar embeddings to the query provided
question = "What is a common belief?"
# Return up to 10 matches to spot check returned chunks from the vector store
chunks = vector_store.similarity_search(question, k=10)
# Display the chunks
print(chunks)
By examining the chunks from the similarity search, we can spot check whether the process worked.
The chunks should be an array with items similar to:
[
Document(
page_content='A common belief is that people choose to save when young,
expecting thereby to maintain their living standards after retirement.
Any assets that remain at death, this theory says, will usually be left
to their families or, possibly, to friends and philanthropy.',
metadata={'source': 'content/letters/pdfs/2022ltr.pdf'}),
...
]
Query Stage - Source Code Overview
The following code connects to the vector store, retrieves the appropriate embeddings, and sends them to the LLM for query response generation.
connection_string = os.getenv("EMBEDDINGS_DB_CONNECTION_STRING")
collection_name = "letters"
embeddings = OpenAIEmbeddings()
# model is GPT 3.5 Turbo, chosen for cost-effectiveness
# temperature is 0, selected to minimize randomness
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
vector_store = PGVector.from_existing_index(
embedding=embeddings,
collection_name=collection_name,
connection_string=connection_string,
# pre_delete_collection=True
)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vector_store.as_retriever())
# Response will contain the answer to the question provide above
response = qa_chain({"query": question})
print(response)
The response should be something similar to:
{
'query': 'What is a common belief?',
'result': 'A common belief is that people choose to save when young,
expecting thereby to maintain their living standards after retirement.'
}
Streamlit Application for the Berkshire Hathaway Letters
The following is a screenshot from the Streamlit application I put together to use the above query logic. Up to ten chunks are displayed along with the associated source filename and the question’s answer. I’ve omitted the other nine chunks from the screenshot.
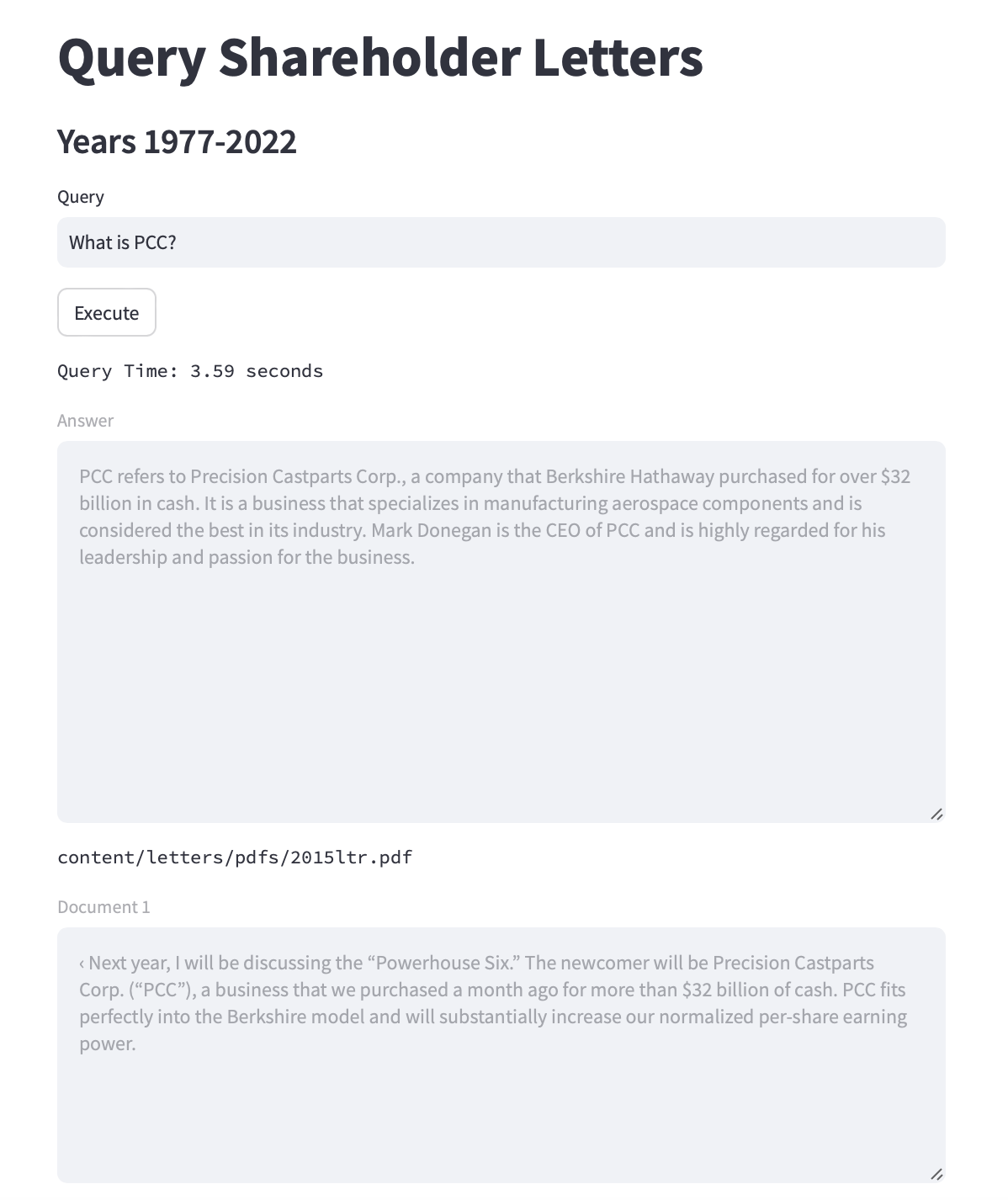
Further reading
- RetrievalQA Chain
- OpenAI Embeddings Class
- PGVector Vector Store for Langchain
- Streamlit
- Neon (Postgres Host for the Vector Store)
Libraries Used
The following is from the requirements.txt file from the project. Note that many of the requirements are only needed for PDF, text files require significantly fewer dependencies and use a different module for Langchain.
langchain
chromadb
bs4
openai
tiktoken
# streamlit
streamlit
# postgres/pgvector
psycopg2
pgvector
# pdfs
pypdf
unstructured
pdf2image
pdfminer
pdfminer.six